
When working on a large code base (think mono-repo with around 9 million lines of Python code), it can be a real challenge to navigate and find the places where you need to make changes.
Most code editors and tools allow to search using glob pattern syntax or fuzzy search. This is useful, but requires you to know at least in parts how a file/function/class is called and spelled.
But what if you only have a rough idea what a function/class might be called and what it's doing? Enter:
Semantic search with vector embeddings ✨
This allows you to find functions or classes based on a semantic understanding of their purpose rather than an exact identifier.
The approach outlined below includes both the name of the function/class as well as the docstring. In my experience, this makes it really easy to quickly find the relevant places, even in a huge code base.
And the best thing: This approach works entirely locally, so none of your code is sent to the cloud!
For more background on vector embeddings, check out the blog post Embeddings: What they are and why they matter by Simon Willison.
How it works ⚙️
Here are the high level steps and tools you need to use this on your Python code base:
- Collect function and class signatures using symbex
- Create vector embeddings using llm embed and an embeddings model (e.g. all-MiniLM-L6-v2), storing them to a SQLite database
- For a given search string, generate embeddings vector and return similar documents
Example 👀
Here is an example of doing a semantic search with the query send email notification on the official Django repository.
llm similar django -c "send email notification" | \
jq -r '"**Score:** \(.score | tostring | .[0:4])\n**ID:** \(.id)\n\n```
python\n\(.content \n
```\n"' | \
rich - -m
It uses jq and rich-cli to format the output.
The following screenshot shows the first 3 results from the output.
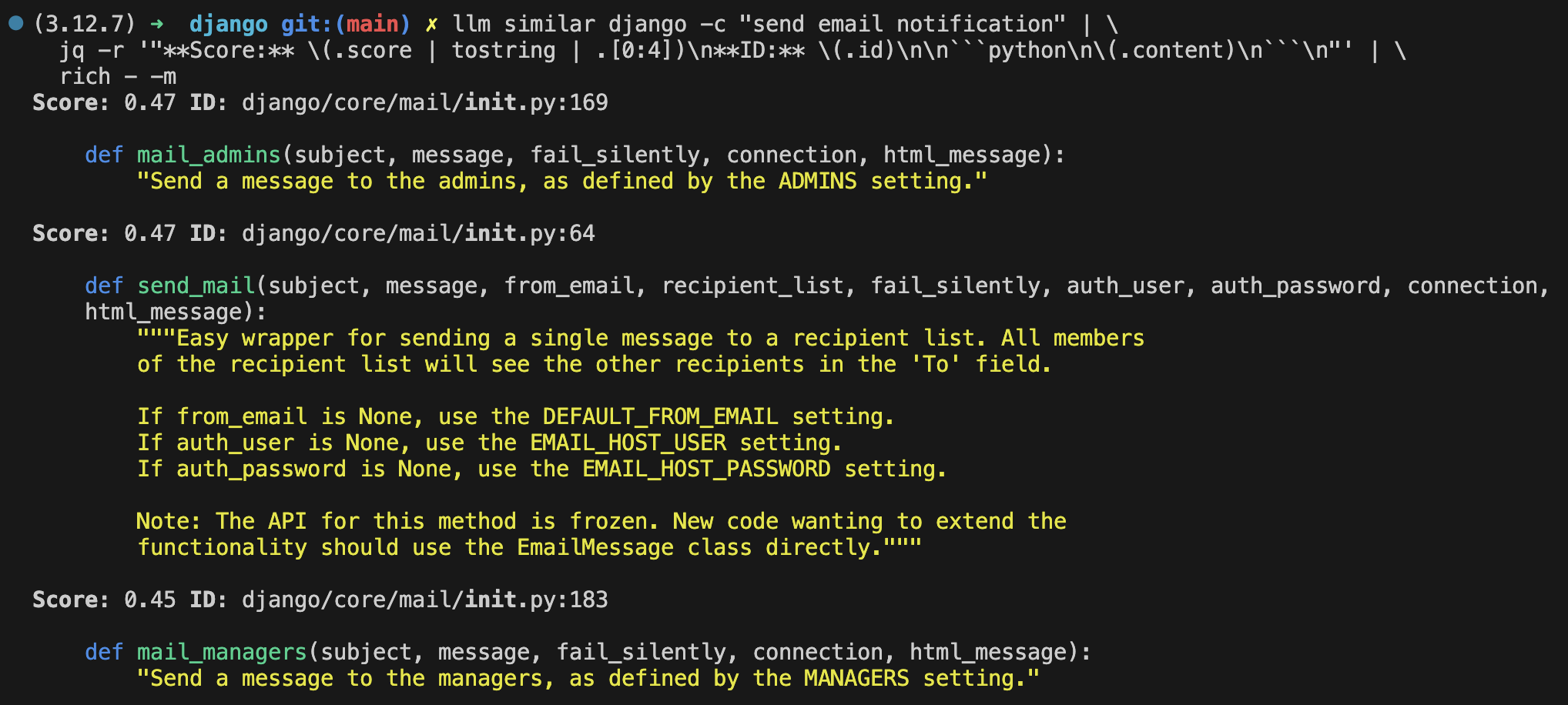
The output includes a score, which is a measure of the vector similarity. It also shows the path and line number of the code, which can be used to quickly navigate to the code in your IDE.
Detailed recipe 🧑💻
Here are the detailed steps you can follow. Some steps need to be amended for your codebase.
# install dependencies
uv tool install llm
uv tool install symbex
uv tool install rich-cli
# install plugin to support local embedding models
llm install llm-sentence-transformers
# test and download model
llm embed -c 'This is some content' -m sentence-transformers/all-MiniLM-L6-v2
# set alias
llm aliases set mini-l6 sentence-transformers/all-MiniLM-L6-v2
# use alias
llm embed -c 'This is some content' -m mini-l6
# set default to local model
llm embed-models default mini-l6
# count functions and classes
# Replace django/ with the path to the source directory of your repository
symbex '*' -d django/ --count
# 3064
# store signatures to temporary json file
symbex '*' -d django/ --json -s --docs | \
jq "map({id, content: .code})" > django.json
# generate embeddings and add to collection (~15 sec)
llm embed-multi django django.json --store
# run search and format output
llm similar django -c "paginate a queryset" | \
jq -r '"**Score:** \(.score | tostring | .[0:4])\n**ID:** \(.id)\n\n```
python\n\(.content)\n
```\n"' | \
rich - -m
How to take this further 🚀
Here are some ideas of how to take this approach even further.
- Use vector similarity to identify similar/duplicated code, and reduce code duplication.
- Creating embeddings locally takes time, and they need to be updated as the code changes. The recipe above uses path and line number as ID. In-place updating embeddings based on this might hard, as the line number potentially changes too often. A better approach might be using the import path instead, which is probably a bit more stable. This can be done with the symbex
--imports/-ioption. - Build a RAG (Retrieval augmented generation) coding assistant, by feeding the results into an LLM along with a prompt.
- Extended the embeddings to include class methods by using
symbex '*.*' - Instead of just using the function signature and doc string, one could use the entire code, and use a code embeddings model like Nomic Embed Code. Simon Willison wrote about this here.
Formatting Alias 💅
Create this alias for the code formatting part, for example for zsh in $ZSH_CUSTOM/aliases.zsh.
# format embeddings results
embed-format() {
jq -r '"**Score:** \(.score | tostring | .[0:4])\n**ID:** \(.id)\n\n```
python\n\(.content)\n
```\n"' | \
rich - -m
}
llm similar django -c "check user is logged in" | embed-format
That's a wrap. May you be able to quickly navigate your Python code base!